Sample Averaging for K-Arm Bandits#
[6]:
from prt_sim.jhu.bandits import KArmBandits
import prt_sim.jhu.plot as pplt
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
[2]:
def epsilon_greedy(actions: list[int], epsilon: float) -> int:
"""
Epsilon-greedy policy chooses the action with the highest value and samples all actions randomly with probability epsilon.
If :math:`b > \epsilon` , use Greedy; otherwise choose randomly from amount all actions
Args:
actions (list[int]): list of action values
epsilon (float): probability of choosing a random exploratory action
Returns:
int: Selected action
"""
# Select action with largest value, choose randomly if there is more than 1
a_star = np.where(actions == np.max(actions))[0]
if len(a_star) > 1:
a_star = np.random.choice(a_star)
else:
a_star = a_star[0]
if np.random.random() > epsilon:
action = a_star
else:
# Choose random from actions
action = np.random.choice(len(actions))
return action
class SampleAverage:
"""
Sample Average method estimates the value of action by estimating the average sample of relevant rewards.
"""
def __init__(self,
num_actions: int,
epsilon: float,
) -> None:
self.num_actions = num_actions
self.epsilon = epsilon
self.q_values = np.zeros(self.num_actions)
self.selections = np.zeros(self.num_actions)
def select_action(self) -> int:
"""
Selects the best action.
Returns:
"""
action = epsilon_greedy(self.q_values, self.epsilon)
return action
def learn(self, action: int, reward: float) -> None:
"""
Updates the visit list and the average action value
Args:
action (int): Selected action that was taken
reward (float): Reward received
Returns:
None
"""
self.selections[action] += 1
# Incremental average update
self.q_values[action] += 1/(self.selections[action]) * (reward - self.q_values[action])
[7]:
num_runs = 2000
num_episodes = 1000
env = KArmBandits()
actions = np.zeros((num_runs, num_episodes), dtype=int)
rewards = np.zeros((num_runs, num_episodes))
optimal_bandit = np.zeros(num_runs, dtype=int)
for run in tqdm(range(num_runs)):
env.reset()
optimal_bandit[run] = env.get_optimal_bandit()
agent = SampleAverage(num_actions=env.get_number_of_actions(), epsilon=0.1)
for step in range(num_episodes):
action = agent.select_action()
actions[run][step] = action
_, reward, _ = env.execute_action(action)
rewards[run][step] = reward
agent.learn(action, reward)
100%|██████████| 2000/2000 [00:10<00:00, 195.70it/s]
[8]:
pplt.plot_bandit_rewards(rewards)
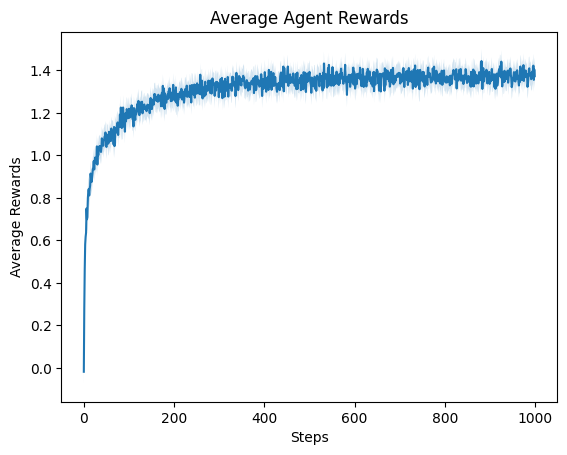
[9]:
pplt.plot_bandit_percent_optimal_action(optimal_bandit, actions)
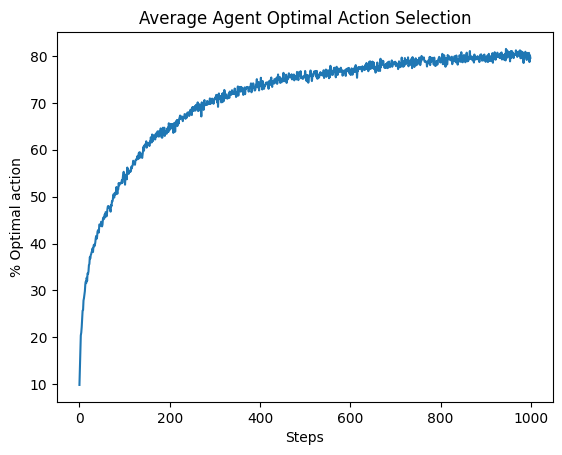
PRT-RL Sample Averaging#
[2]:
from prt_rl.exact.sample_average import SampleAverage
from prt_rl.common.policies import QTablePolicy
from prt_rl.env.wrappers import JhuWrapper
[4]:
# Set the number of runs and episodes per run
num_runs = 2000
num_episodes = 1000
# Initialize Environment
env = JhuWrapper(jhu_name="PRT-SIM/RobotGame-v0")
policy = QTablePolicy(env_params=env.get_parameters())
agent = SampleAverage(policy=policy)
agent.train(env=env, total_steps=10000)
0%| | 0/10000 [00:00<?, ?it/s]
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Cell In[4], line 11
8 policy = QTablePolicy(env_params=env.get_parameters())
9 agent = SampleAverage(policy=policy)
---> 11 agent.train(env=env, total_steps=10000)
File ~/Repos/prt-rl/src/prt_rl/exact/sample_average.py:68, in SampleAverage.train(self, env, total_steps, schedulers, logger, evaluator, show_progress)
65 scheduler.update(current_step=num_steps)
67 # Collect a single step of experience
---> 68 experience = collector.collect_experience(policy=self.policy, num_steps=1)
69 state = experience['state']
70 action = experience['action']
File ~/Repos/prt-rl/src/prt_rl/common/collectors.py:276, in SequentialCollector.collect_experience(self, policy, num_steps, bootstrap)
272 last_value_estimate = None
274 for _ in range(num_steps):
275 # Collect a single step
--> 276 state, action, next_state, reward, done, value_est, log_prob = self._collect_step(policy)
278 states.append(state)
279 actions.append(action)
File ~/Repos/prt-rl/src/prt_rl/common/collectors.py:501, in SequentialCollector._collect_step(self, policy)
498 else:
499 state = self.previous_experience["next_state"]
--> 501 action, value_est, log_prob = get_action_from_policy(policy, state, self.env_params)
502 next_state, reward, done, _ = self.env.step(action)
504 # Update the Metrics tracker and logging
File ~/Repos/prt-rl/src/prt_rl/common/collectors.py:79, in get_action_from_policy(policy, state, env_params, deterministic, inference_mode)
77 return random_action(env_params, state), None, None
78 else:
---> 79 prediction = policy.predict(state, deterministic=deterministic)
81 # If only the action is returned then set the value estimate and log probs to None
82 if len(prediction) == 1:
File ~/Repos/prt-rl/src/prt_rl/common/policies.py:310, in QTablePolicy.predict(self, state, deterministic)
297 """
298 Chooses an action based on the current state and returns the action, value estimate, and log probability.
299
(...) 307 - log_prob (torch.Tensor): None
308 """
309 # Get the action values for the current state
--> 310 action_vals = self.qtable.get_action_values(state)
312 if not deterministic:
313 action = self.decision_function.select_action(action_vals)
File ~/Repos/prt-rl/src/prt_rl/common/qtable.py:78, in QTable.get_action_values(self, state)
66 def get_action_values(self,
67 state: torch.Tensor
68 ) -> torch.Tensor:
69 """
70 Returns the state action values for a given state.
71
(...) 76 torch.Tensor: action values for given state with shape (# env, # actions)
77 """
---> 78 assert state.dtype == torch.int, "State values must be integers."
79 state = state.squeeze(-1)
80 return self.q_table[torch.arange(self.q_table.size(0)), state]
AssertionError: State values must be integers.
[ ]: