gold_explorer#
Functions#
Classes#
- class prt_sim.jhu.gold_explorer.GoldExplorer(render_mode: str | None = 'rgb_array')[source]#
The Gold Explorer puzzle
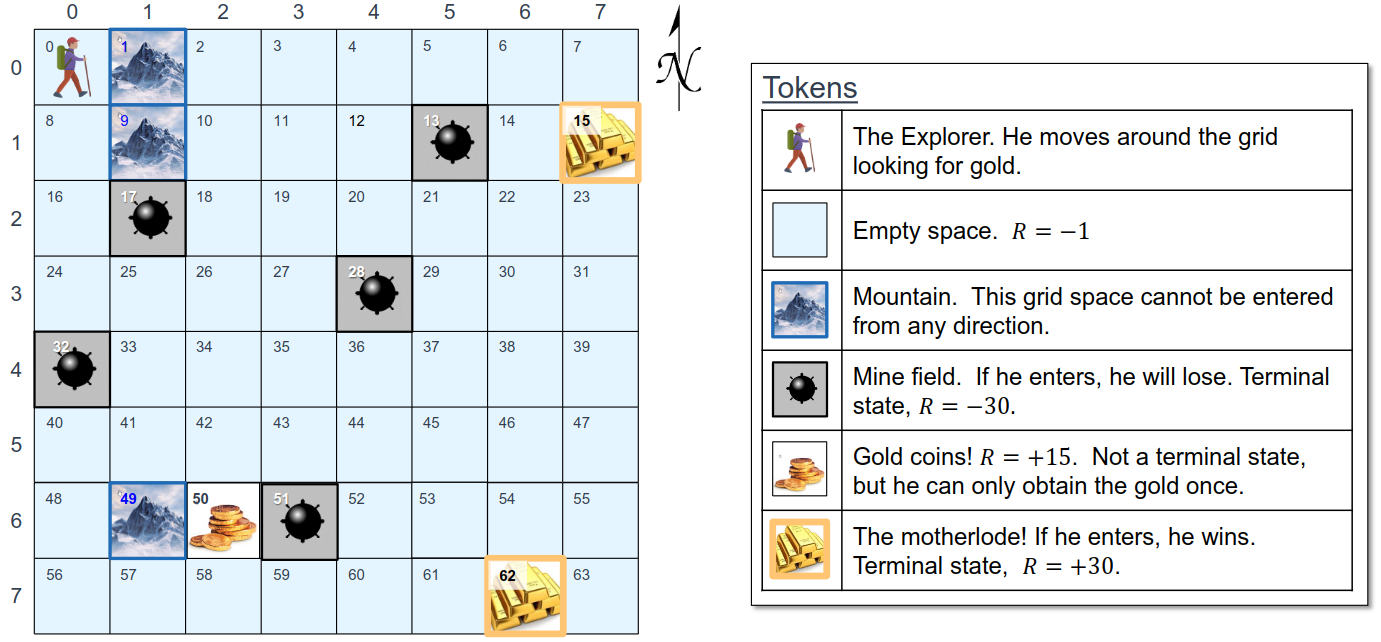
Action space: integer representing a discrete action described in the table below
Num
Action
0
North
1
East
2
South
3
West
Observation space: integer between 0 and 127 representing the state as an octal number, <gold bit><row><column>
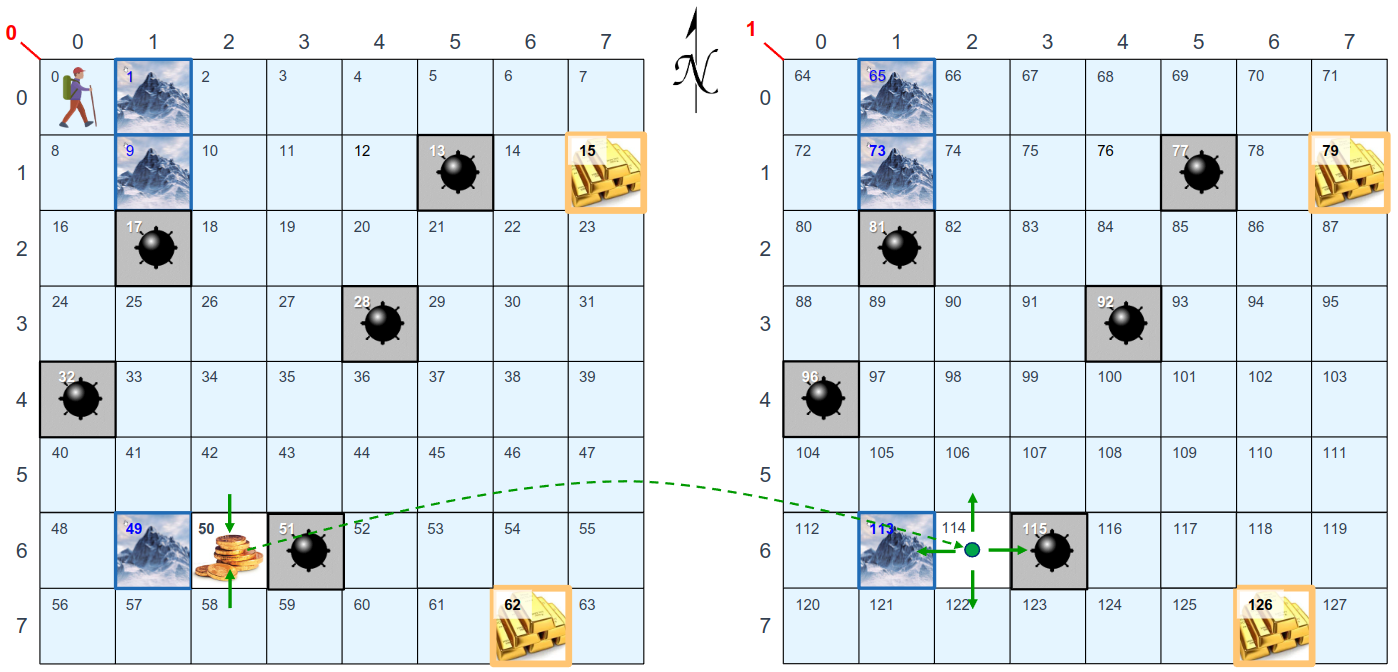
Reward: +15 for obtaining gold coins, +30 for obtaining the motherlode, -30 for entering a mine field, -1 for every other location
- execute_action(action: int) Tuple[int, float, bool][source]#
Executes an action for the explorer.
- Parameters:
action (int) – the action to execute
Returns:
- get_number_of_actions() int[source]#
Returns the number of discrete actions in the puzzle
- Returns:
total number of actions in the puzzle
- Return type:
- get_number_of_states() int[source]#
Returns the number of states in the puzzle
- Returns:
total number of states in the puzzle
- Return type: